Why is data management hard for procurement? The challenge of data combination

What is procurement data?
Procurement data includes vendor data, master data, contract data, bills of material, performance data, sustainability score cards, transaction data, purchase order details, and much more. There are two dimensions of procurement data. First, procurement data can be internal or external. Secondly, procurement data can be structured or unstructured. When combined, these dimensions make up four distinct types of procurement data: internal structured, internal unstructured, external structured, and external unstructured.
- Internal structured data—data stored and created within the existing corporate software, like vendor master data.
- Internal unstructured data—data stored and created locally that is hard to integrate, like purchase agreements. It may be text-based, exist in many versions and places, be in different file formats, or be overall hard to analyze without human oversight.
- External structured data—data that comes from outside the organization’s own database. A good example of this type of data is supplier specific sustainability scores. While this data has some barriers to access, it is designed to be easy to integrate for procurement needs.
- External unstructured data—data that is both to access and integrate. It comes from a variety of external sources but is not specially designed for procurement specific use cases, like social feeds or weather data. This type of data is very useful for analytics and forecasting (e.g. by comparing category performance against market outlook reports) but requires a lot of work to integrate with existing internal data.
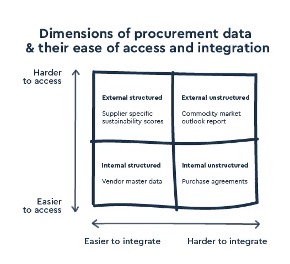
As the technological capabilities for procurement data and analytics increase, modern procurement organizations can improve their ability to make use of these four types of data. While traditional procurement was largely fixated on internal structured data, modern agile procurement has incorporated a wider array of data.
Spend analytics is one of the most common ways to access the wide scope of data available for procurement. Spend analytics encompasses the collecting, cleansing, classifying, consolidating, and merging of internal spend data with other data sets (i.e. external data) in order to perform analysis.
Spend analytics can be performed with all types of procurement data but varies in its levels of complexity. For instance, spend analytics that is done only with internal structured data (or master data from ERPs and financial systems) is relatively straightforward.
However, even the most “straightforward” of spend analytics efforts can run into some challenges. All this incoming data isn’t neat and tidy. The more external and unstructured data is incorporated, the more complex—and insightful—the process can be. The harder to integrate and access, the more difficult it is to make use of such data.
The challenges of procurement data analytics
The following challenges of procurement data analytics are seen time and time again when organizations begin the procurement data analytics journey.
- Poor data quality: even structured data can contain many errors that limit the depth and quality of analysis available. Although it’s important to realize that data will never be “perfect” (this is in fact a trap that stops a lot of organizations from even attempting spend analytics, explained below) it must be at an adequate level. Errors usually boil down to hygiene, like empty or misspelled data fields.
- Complex and labor-intensive cleansing and classification: Cleansing is about detecting inaccuracies and removing corrupt records and redundancies from a set of data. Classification is the act of analyzing structured or unstructured data and organizing it into categories based on content, type, and other metadata. For most large organizations, human labor is not enough—robust, automated process are needed to make data useful.
- Lack of data-driven leadership: without the consistent involvement and sponsorship of data-driven leaders, spend analytics usually falls short. The reason is because without the proper understanding of the potential value, analytics efforts in procurement can feel like a waste of time (they aren’t)!
- Unrealistic goals: rushing into a procurement analytics or spend analytics project with too big a scope or lack of planning will be detrimental. Starting small with immediate, disciplined, and regular feedback loops is a must.
- Using the wrong tools: based on the desired level of analytics maturity, the choice of solutions can vary greatly. While basic spreadsheet programs can easily manage straight forward spend analytics, they will not be able to manage unstructured or external data well. Best-of-breed solutions can offer a variety of powerful tools, including AI-trained classification and external data enrichment.
- Limited analytics capabilities: you shouldn’t have to be a data scientist to uncover the potential of spend analytics. That being said, if you want a real return on investment from procurement data analytics, you must have an intuitive solution with the suitable technical capabilities that meets the needs of procurement while catering to varying levels of competence.
- Lack of domain competence: the process of classifying data, for instance, is one case in which domain specific knowledge is a must. Outsourcing a data set for category grouping or vendor matching can fail if those doing the classifications don’t understand the goods and industry.
- Fear of losing control over data: the whole point of procurement data analytics is to break data out of its siloes. But this requires a level of trust from different data owners. Everyone must be on board and willing to share their data for the benefits of analysis.
- Analytics as a one-time effort: Finally, procurement data analytics should be a long-term process and part of the total procurement transformation. Without repeated analysis, procurement data analytics doesn’t offer the same value.
Does procurement data need to be perfect?
No! Even though we list “poor data quality” as one of the key challenges to data analytics, there is no reason why it needs to be perfect. The old adage “garbage in, garbage out” makes it sound like any data that isn’t perfect is unusable. But spend analytics with good (but not great) data quality is still better than no analytics. You shouldn’t be looking to get perfect numbers with spend analytics. Rather, you should be empowering data-driven decision making as soon as possible.
Analytics is for better decisions, not for perfect ones. Think of data analytics like a mining company. In the mining process, tons of rocks are dug up to get to a very tiny bit of ore. That ore is processed and refined until a metal is produced. Miners dig lots of different materials, get rid of stuff they don’t need, and enrich and refine until they get something valuable. Procurement analytics should be thought of the same way. It digs up dirty data with known value, puts a robust process in place for enriching and refining it, and finds the precious stuff.
Even if you would have a “perfect” back-end system set-up for your procurement analytics, your business will change faster than these back-end systems can. Your analytics must adapt faster than your back-end systems. Since so much of the valuable external data is produced and shared through the internet, you’re never going to stop the influx of dirty data. Seeing as perfect data isn’t feasible, it’s up to organizations to start promoting more trust in their people. “Garbage in, garbage out” implies that decision making is impossible without perfect data and discounts the abilities of people in the organization. While it can’t be said that all users know best, together they know more than just one person can. Data must be surfaced with all its imperfections.
When you subscribe to the blog, we will send you an e-mail when there are new updates on the site so you wouldn't miss them.